
ThreadLocal源码
数据结构
ThreadLocalMap 是 ThreadLocal 的静态内部类,它内部维护了一个 Entry 数组,key 是 ThreadLocal 对象,value 是线程的局部变量本身。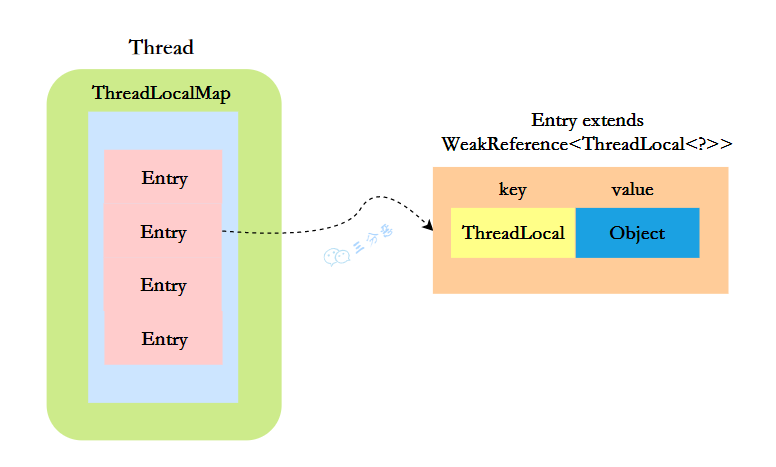
1
2
3
4
5
6
7
8
9
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}可以看到,这里的 Entry 继承了 WeakReference,它限定了 key 是一个弱引用,弱引用的好处是当内存不足时,JVM 会回收 ThreadLocal 对象,并且将其对应的 Entry 的 value 设置为 null,这样在很大程度上可以避免内存泄漏。
弱引用需要用 java.lang.ref.WeakReference 类来实现,它比软引用的生存期更短,对于只有弱引用的对象来说,只要垃圾回收机制一运行,不管 JVM 的内存空间是否足够,都会回收该对象占用的内存。
内存泄露
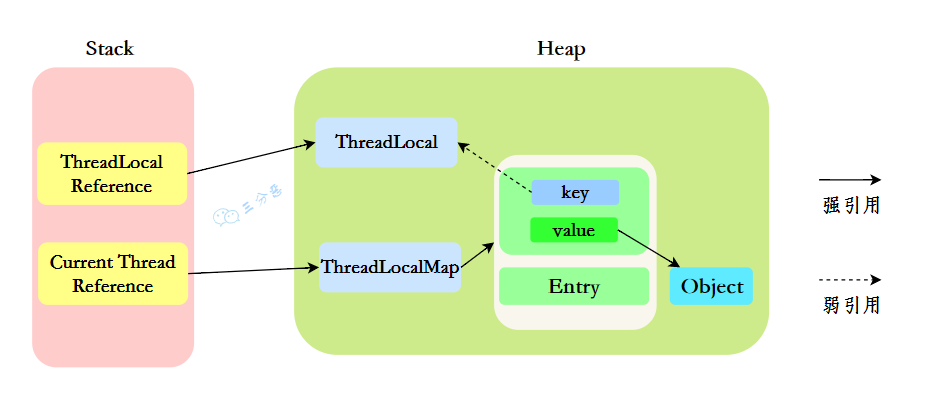
假如你在一个方法中使用了 ThreadLocal
1
2
ThreadLocal<String> t1 = new ThreadLocal<>();
String s = t1.get();这里 t1 指向创建的 ThreadLocal,当这个方法执行完,t1 被销毁,所以 ThreadLocal 左边的箭头断掉了,当触发 gc 时,由于 key 是弱引用,key 指向 ThreadLocal 的箭头也会断掉,这样创建的 ThreadLocal 对象就会被回收,就导致了 key 为 null,但是由于 value 是强引用,没被回收,这就代表无法获取到这个 value 了,这就是内存泄漏
通常情况下,随着线程 Thread 的结束,其内部的 ThreadLocalMap 也会被回收,从而避免了内存泄漏。
但如果一个线程一直在运行,并且其 ThreadLocalMap 中的 Entry.value 一直指向某个强引用对象,那么这个对象就不会被回收,从而导致内存泄漏。当 Entry 非常多时,可能就会引发更严重的内存溢出问题。
所以最好的方式就是使用完后调用remove(),remove() 方法会将当前线程的 ThreadLocalMap 中的所有 key 为 null 的 Entry 全部清除,这样就能避免内存泄漏问题。
1
2
3
4
5
6
7
ThreadLocal<String> t1 = null;
try {
t1 = new ThreadLocal<>();
String s = t1.get();
} finally {
t1.remove();
}源码
get 方法
1
2
3
4
5
6
7
8
9
10
11
12
13
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}通过 getMap 方法传入当前线程作为实参
1
2
3
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}这里的 t.threadLocals 就是 Thread 内部的成员变量ThreadLocal.ThreadLocalMap threadLocals = null;
调用map.getEntry()传入当前 ThreadLocal 对象
1
2
3
4
5
6
7
8
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}首先会找到传入的 ThreadLocal 对象的下标,这里的 threadLocalHashCode 计算有点东西,每创建一个 ThreadLocal 对象,它就会新增0x61c88647,这个值很特殊,它是斐波那契数 也叫 黄金分割数。hash 增量为 这个数字,带来的好处就是 hash 分布非常均匀。
如果e为空或者e.get() != key当就调用getEntryAfterMiss方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get();
if (k == key)
return e;
if (k == null)
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}这个方法的形参是当前 ThreadLocal 对象、其下标、下标对应的 Entry
进入一个循环:
- 通过
e获取 key - 如果这个 key 和传入的 key 相等,就返回这个 e,
- 如果这个 key 为空,就需要回收这个 key 对应的 value,进入
expungeStaleEntry(i)方法, - 否则通过
nextIndex(i, len)更新下标 i,实际就是加 1 或者置为 0(这是因为其解决 hash 冲突是通过开放定址法) - 最后,更新 e。
对于expungeStaleEntry方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// expunge entry at staleSlot
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}这个方法会从 staleSlot+1 开始处理,遇到空的槽位就退出循环,循环过程中,如果当前槽位的 key 为 null,就把这个槽位的 value 置为 null,size–,否则就看当前槽位的 key 的散列值等不等于下标,不等于就移动到正确的位置上去,函数的返回值就是遍历过程中遇到的第一个为空的槽位的下标,让 ai 重述一下
- 函数确实从 staleSlot 之后的第一个槽位开始处理(即 nextIndex(staleSlot, len)),目的是检查并处理可能因哈希冲突而受影响的后续条目。
- 当循环遇到数组中的空槽(即 tab[i] == null)时,循环结束,此时返回的 i 即为第一个遇到的空槽的索引。
- 在循环内,如果发现当前条目(Entry e)的键为 null,表明该条目也已过期,这时会将该条目的 value 设为 null,并将条目整体设为 null,同时减少表的大小(size–)。
- 对于键不为 null 的条目,函数会根据其键的哈希值确定其在理想情况下的位置(h = k.threadLocalHashCode & (len - 1))。如果这个计算出的位置 h 与当前条目的实际位置 i 不同,说明该条目因之前的哈希冲突未放在正确位置,这时会将当前位置设为 null,并通过循环查找下一个空位,然后将条目移动到这个正确的空位上。
- 最终,函数返回的 i 不仅标志着循环终止的位置,还意味着从 staleSlot 到返回的索引之间的所有槽位都已被检查并处理过过期条目。
总结
- 如果当前 ThreadLocal 等于算出的第一个下标上的 key,那么就直接返回,如果不相等或者 key 为 null,就进入
getEntryAfterMiss方法- 在
getEntryAfterMiss的循环中,如果通过开放定址法找到了匹配的 key,就直接返回,如果循环中遇到了为 null 的 key,就进入expungeStaleEntry方法,如果遇到了空的 tab[i],就返回退出循环返回 nullexpungeStaleEntry会在遇到第一个为空的槽位之前,清理过期的 key,既把当前槽位的 value((e = tab[i]).value)、当前槽位置为 null(tab[i]),并且会重新计算每个节点的散列值,将其移动到正确的下标上。
set 方法
1
2
3
4
5
6
7
8
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}本质是调用ThreadLocalMap的 set 方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}首先计算当前 ThreadLocal 对象的散列值,即下标,进入循环
- 获取当前
e对应的 key,如果这个 key 等于我们传入的 ThreadLocal 对象,那么就进行赋值并 return - 如果当前
e对应的 key 为空,则进入replaceStaleEntry(key, value, i)方法 - 如果一开始算出的下标对应的槽位为空,即 e == null,那么就不会进入循环,而是直接赋值
tab[i] = new Entry(key, value),让数组大小++ - 最后,进入
cleanSomeSlots(i, sz)方法,如果cleanSomeSlots返回 true,代表清理了过期 key,返回 false,判断当前 size 是不是大于等于阈值(2/3 *len),true,就进入 rehash。






