
RabbitMQ
1. 基本架构
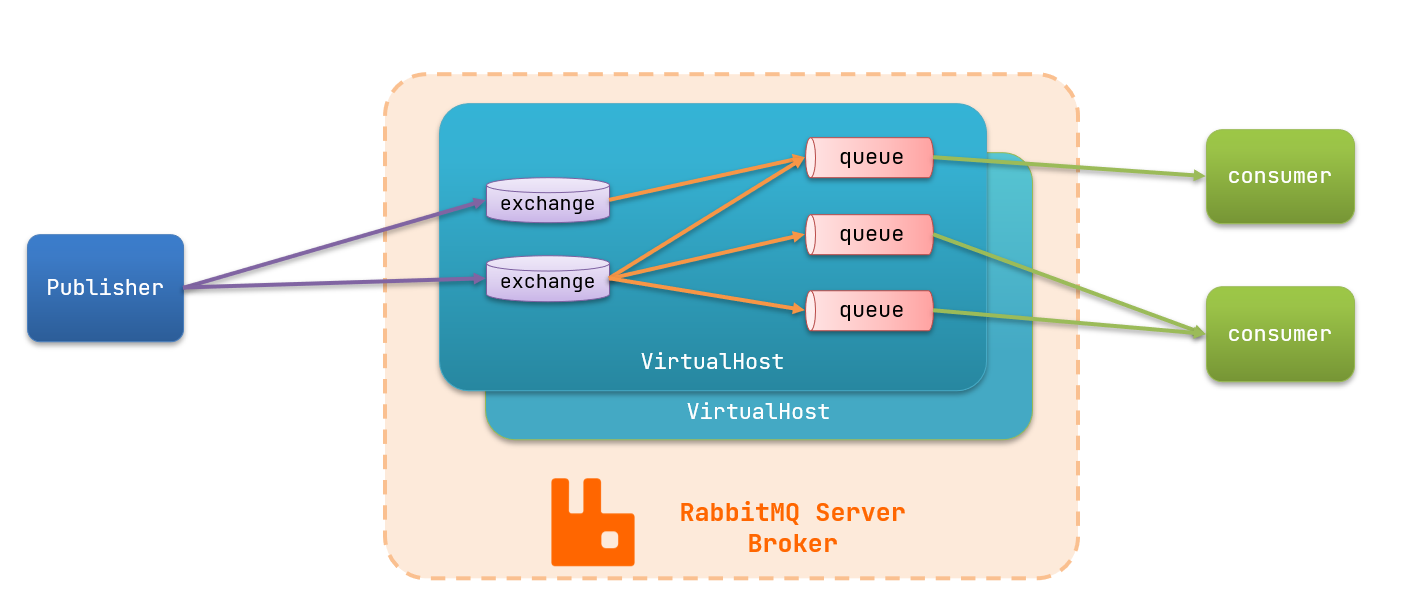
- publisher:生产者
- consumer:消费者
- exchange 个:交换机,负责消息路由
- queue:队列,存储消息
- virtualHost:虚拟主机,隔离不同租户的 exchange、queue、消息的隔离
2. 消息模型
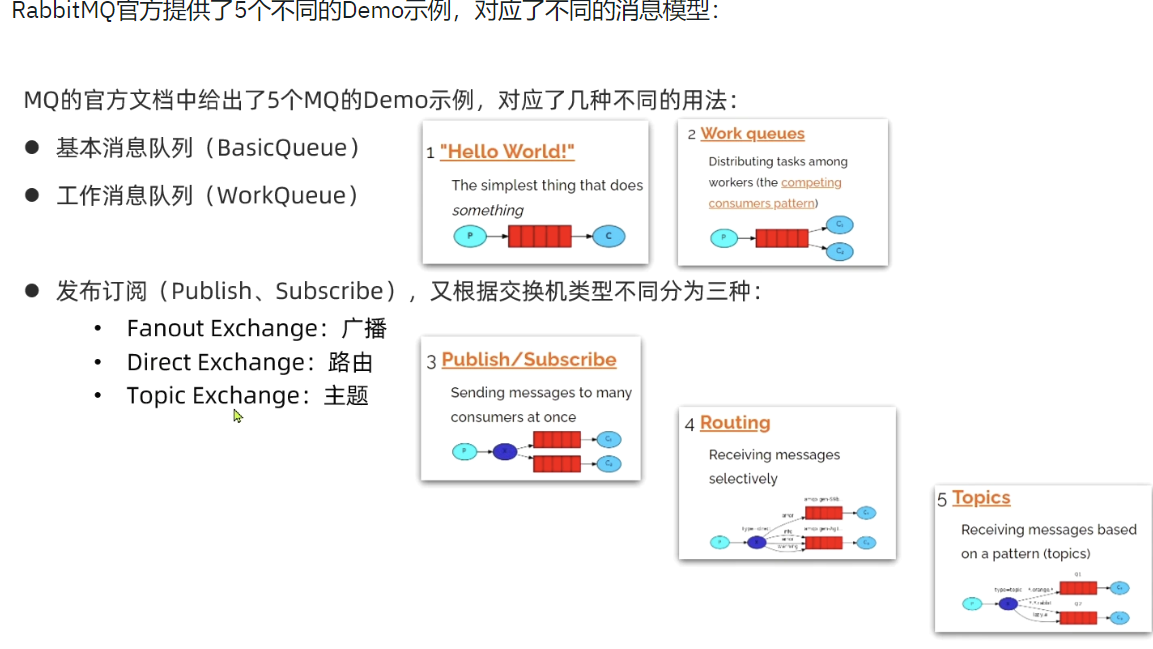
WorkQueue: 让多个消费者绑定到一个队列,共同消费队列中的消息。
Topic: 在绑定队列和交换机的时候指定路由键
1
2
3
4@Bean public Binding bindingTopicQueue1(Queue topicQueue1, TopicExchange topicExchange){ return BindingBuilder.bind(topicQueue1).to(topicExchange).with("d.*"); }在发送消息时设置路由键,根据路由键路由到相应的队列
1
rabbitTemplate.convertAndSend("danaizio.topic","d",JSON.toJSONString(userDO));- d.#,匹配 d、d.1,d.1.1
- d.*,匹配 key.1
3. 如何保证消息不丢失
3.1 丢失原因
- 发送时丢失:
- 生产者发送的消息未送达 exchange
- 消息到达 exchange 后未到达 queue
- MQ 宕机,queue 将消息丢失
- consumer 接收到消息后未消费就宕机
针对这些问题,RabbitMQ 分别给出了解决方案:
- 生产者确认机制
- mq 持久化
- 消费者确认机制
- 失败重试机制
3.2 生产者消息确认
RabbitMQ提供了publisher confirm机制来避免消息发送到MQ过程中丢失。这种机制必须给每个消息指定一个唯一ID,以区分不同消息,避免ack冲突。消息发送到MQ以后,会返回一个结果给发送者,表示消息是否处理成功。
返回结果有两种方式:
- publisher-confirm,发送者确认
- 消息成功投递到交换机,返回ack
- 消息未投递到交换机,返回nack
- publisher-return,发送者回执
- 消息投递到交换机了,但是没有路由到队列。返回ACK,及路由失败原因。
首先修改配置文件
1
2
3
4
5
6
7
8
9
10
11
spring:
rabbitmq:
host: 192.168.198.128 # 主机名
port: 5672 # 端口
virtual-host: learn # 虚拟主机
username: guest # 用户名
password: guest # 密码
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true说明:
publish-confirm-type:开启publisher-confirm,这里支持两种类型:
simple:同步等待confirm结果,直到超时correlated:异步回调,定义ConfirmCallback,MQ返回结果时会回调这个ConfirmCallbackpublish-returns:开启publish-return功能,同样是基于callback机制,不过是定义ReturnCallbacktemplate.mandatory:定义消息路由失败时的策略。true,则调用ReturnCallback;false:则直接丢弃消息
定义ReturnCallback
每个RabbitTemplate只能配置一个ReturnCallback,因此需要在项目加载时配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@Configuration
@Slf4j
public class RabbitMQConfig implements ApplicationContextAware {
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class);
rabbitTemplate.setReturnsCallback(new RabbitTemplate.ReturnsCallback() {
@Override
public void returnedMessage(ReturnedMessage returnedMessage) {
log.info("消息发送失败,应答码{},原因{},交换机{},路由键{},消息{}",
returnedMessage.getReplyCode(),
returnedMessage.getReplyText(),
returnedMessage.getExchange(),
returnedMessage.getRoutingKey(),
returnedMessage.getMessage());
}
});
}
}当消息成功到达交换机确没被任何一个队列接收,那么就会触发这个回调函数
定义ConfirmCallback
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public String send2() {
UserDO userDO = UserDO.builder()
.id(1)
.age(17)
.username("张三")
.build();
String uuid = UUID.randomUUID().toString();
log.info("消息唯一id为:{}",uuid);
CorrelationData correlationData = new CorrelationData(uuid);
correlationData.getFuture().addCallback(
result -> {
assert result != null;
if (result.isAck()) {
log.info("消息发送成功, ID:{}", correlationData.getId());
} else {
log.error("消息发送失败, ID:{}, 原因{}",correlationData.getId(), result.getReason());
}
},
ex -> log.error("消息发送异常, ID:{}, 原因{}",correlationData.getId(),ex.getMessage())
);
rabbitTemplate.convertAndSend("danaizio.direct","d1",JSON.toJSONString(userDO),correlationData);
return "发送成功";
}当消息成功到达交换机时,ack为true
3.2 消费者消息确认
RabbitMQ是阅后即焚机制,RabbitMQ确认消息被消费者消费后会立刻删除。
而RabbitMQ是通过消费者回执来确认消费者是否成功处理消息的:消费者获取消息后,应该向RabbitMQ发送ACK回执,表明自己已经处理消息。
设想这样的场景:
- 1)RabbitMQ投递消息给消费者
- 2)消费者获取消息后,返回ACK给RabbitMQ
- 3)RabbitMQ删除消息
- 4)消费者宕机,消息尚未处理
这样,消息就丢失了。因此消费者返回ACK的时机非常重要。
而SpringAMQP则允许配置三种确认模式:
manual:手动ack,需要在业务代码结束后,调用api发送ack。
auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
1
2
3
4
5
spring:
rabbitmq:
listener:
simple:
acknowledge-mode: none # 关闭ack由此可知:
- none模式下,消息投递是不可靠的,可能丢失
- auto模式类似事务机制,出现异常时返回nack,消息回滚到mq;没有异常,返回ack
- manual:自己根据业务情况,判断什么时候该ack
一般,我们都是使用默认的auto即可。
3.3 消费失败重试机制
当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者,然后再次异常,再次requeue,无限循环,导致mq的消息处理飙升,带来不必要的压力,我们可以利用Spring的retry机制,在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。
1
2
3
4
5
6
7
8
9
10
spring:
rabbitmq:
listener:
simple:
retry:
enabled: true # 开启消费者失败重试
initial-interval: 1000 # 初识的失败等待时长为1秒
multiplier: 1 # 失败的等待时长倍数,下次等待时长 = multiplier * last-interval
max-attempts: 3 # 最大重试次数
stateless: true # true无状态;false有状态。如果业务中包含事务,这里改为false重启consumer服务,重复之前的测试。可以发现:
- 在重试3次后,SpringAMQP会抛出异常AmqpRejectAndDontRequeueException,说明本地重试触发了
- 查看RabbitMQ控制台,发现消息被删除了,说明最后SpringAMQP返回的是ack,mq删除消息了
3.4 失败策略
在之前的测试中,达到最大重试次数后,消息会被丢弃,这是由Spring内部机制决定的。
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecovery接口来处理,它包含三种不同的实现:
RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
比较优雅的一种处理方案是RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门存放异常消息的队列,后续由人工集中处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
//设置死信交换机和死信队列
@Configuration
public class DlXConfig {
@Bean
public DirectExchange errorMessageExchange(){
return new DirectExchange("error.direct");
}
@Bean
public Queue errorQueue(){
return new Queue("error.queue", true);
}
@Bean
public Binding errorBinding(Queue errorQueue, DirectExchange errorMessageExchange){
return BindingBuilder.bind(errorQueue).to(errorMessageExchange).with("error");
}
@Bean
public MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){
return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}
}
//为队列绑定死信交换机和死信队列
@Bean
public Queue directQueue1(){
return QueueBuilder
.durable("direct.queue1")
.deadLetterExchange("error.direct")
.deadLetterRoutingKey("error")
.ttl(2000)
.build();
}当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter):
- 消费者使用basic.reject或 basic.nack声明消费失败,并且消息的requeue参数设置为false
- 消息是一个过期消息,超时无人消费
- 要投递的队列消息满了,无法投递
4. 怎么避免消息重复投递和重复消费
当交换机和队列收到消息后,都会返回相应的ack,假如这个ack由于某些原因未能到达发送方,那么就会触发重试机制(仅限队列到消费者,交换机到队列的重试需要程序员自己实现)而导致相同的消息重复消费,因此需要保证消费的幂等性。
可以为消息设置唯一id,根据这个id在消费方进行幂等操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public String send2() {
UserDO userDO = UserDO.builder()
.id(1)
.age(17)
.username("张三")
.build();
String uuid = UUID.randomUUID().toString();
log.info("消息唯一id为:{}",uuid);
CorrelationData correlationData = new CorrelationData(uuid);
correlationData.getFuture().addCallback(
result -> {
assert result != null;
if (result.isAck()) {
log.info("消息发送成功, ID:{}", correlationData.getId());
} else {
log.error("消息发送失败, ID:{}, 原因{}",correlationData.getId(), result.getReason());
}
},
ex -> log.error("消息发送异常, ID:{}, 原因{}",correlationData.getId(),ex.getMessage())
);
rabbitTemplate.convertAndSend("danaizio.direct","d1",JSON.toJSONString(userDO),correlationData);
return "发送成功";
}所以,重复投递不能解决,但是能防止重复消费。
5. 无法路由的消息去哪里
- 如果
spring.rabbitmq.template.mandatory为true,且消息为路由到任何队列,那么消息会会被返回给生产者,并触发ReturnCallback,如果为false,则直接丢弃消息 - 如果有默认交换机,会投递到默认交换机
- 如果已经到达队列但无法到达消费者且该队列绑定了死信队列,会将消息投递到死信队列。
6. channel
RabbitMQ在网络层有connection和channel两个概念,一个connection代表一个tcp连接,这个connection里面又有很多channel(虚拟连接),客户端于MQ之间的通信都是基于channel,避免多次建立tcp连接,避免资源浪费。
7. 消息持久化
首先,交换机和队列都可以设置持久化,这样mq重启之后,他们的元数据可以保留,
对于消息来说,持久化代表消息到达队列之后,会异步存入磁盘,所以如果mq宕机,还是会导致小部分数据丢失,因此mq后来提出了惰性队列。
惰性队列
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存
- 支持数百万条的消息存储


